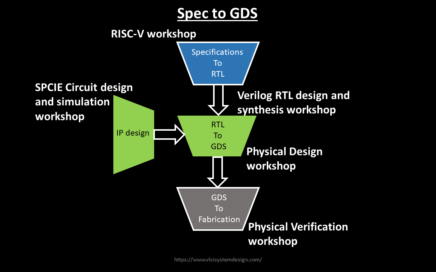
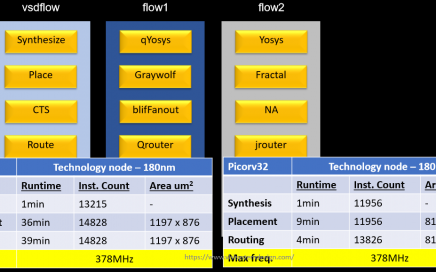
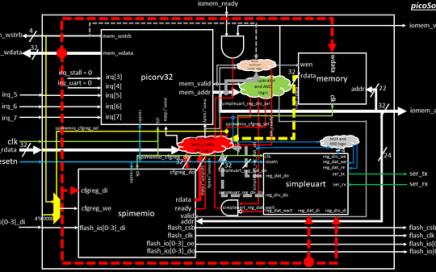
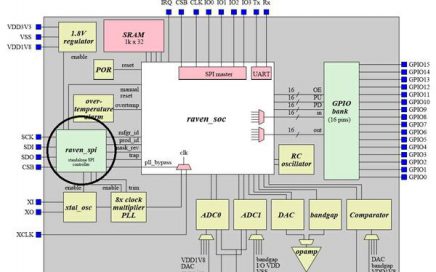
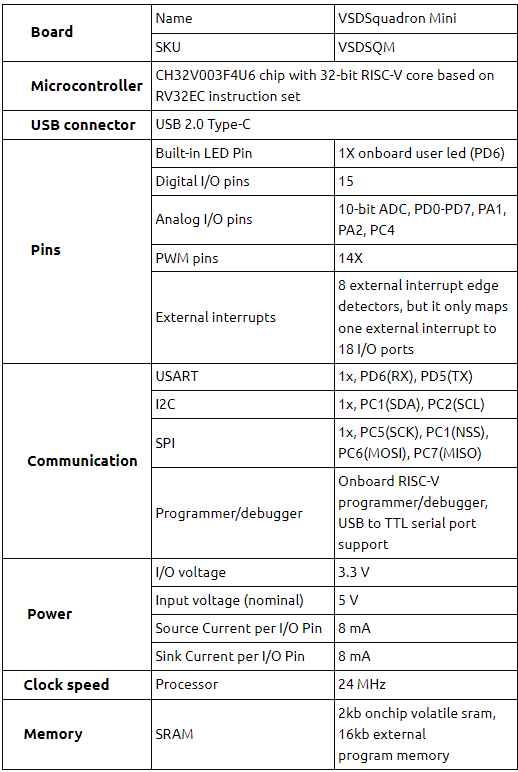
The Power of an Intense VLSI Program by SFAL/VSD
Today, as technology races towards ever-smaller geometries and more complex chips, the need for professionals who are not just well-versed in theory but also skilled in practical, hands-on experience has never been more critical. An intense VLSI program that mirrors industry practices is the beacon that guides aspiring engineers across this bridge.