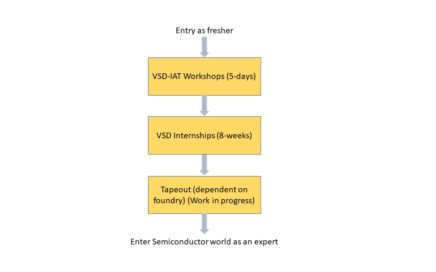
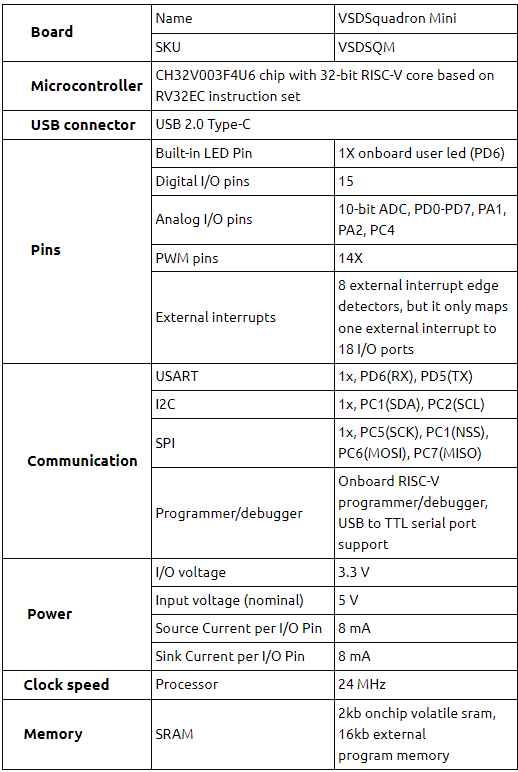
Random Verification in Hardware – A Primer
Join us to explore such concepts and more, where we use Python to leverage its library-rich environment feasible for verification using Vyoma’s UpTickPro platform, in this edition of Capture the Bug hackathon, organized by NIELIT, Calicut, mentored by IIT Madras, in association with VLSI System Design and Vyoma Systems.
Hackathon details – https://nielithackathon.in/