This blog is regarding abstract submission for VSDOpen2018, which is the first online conference in VLSI, that covers all aspects of semiconductor technology with prime focus to build SoC using RISC-V CPU by illustrating exciting ways using (only) opensource EDA tools.
This conference has 6 symposium, out of which fifth symposium is to come up with implementation of any EDA/CAD applications using machine intelligence techniques. List of other symposium and session chair can be found in below link:
https://www.vlsisystemdesign.com/vsdopen2018-2/
This blog is about Symposium V – Machine intelligence in EDA/CAD applications (abstract submission last date is 15th August, please see above link for details)
Let’s investigate a simple Wire Resistance Estimate (WiRE) model
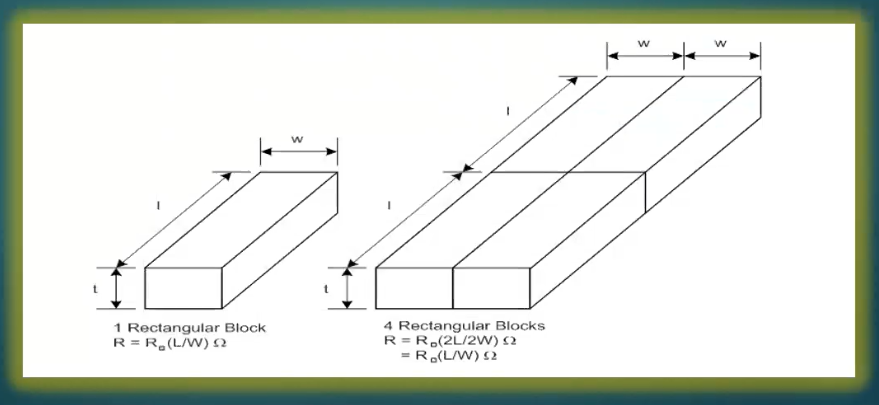
This is common design automation problem which is used for estimating timing and power characteristics for analysis and implementation for many steps in ASIC flow. We will restrict our scope to physical implementation only, where known quantity is “length” of wire and resistance is predicted. A snip of wire is shown below:
Before we start, we are going to tell you that the problem we are going to solve, it won’t be solved perfectly. So, pay attention, and correct us where we can improve. Below is our dataset, which is collected from a 20nm process node. Essentially, it has 4 columns, wire-length, wire-width, temperature and resistance.
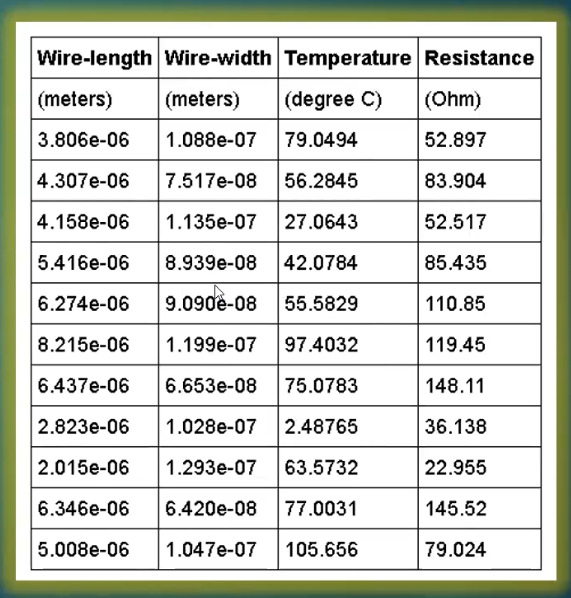
We are going to predict our resistance just from the wire-length. That will be our linear regression i.e., you have one independent variable – wire-length, and one dependent variable – resistance. We have about 10000 samples, so we are going to divide 80% (8000) into training and 20% (2000) into validation. Validation is a set that is not shown to the training model. So training model will train only on 8000 samples and then you will use your other 2000 to find out, if the model you created is working reasonably well on the validation set or not. If it doesn’t, then it is not good enough. Its not generalizing the model.
Let’s get into the terminology what machine learning or data scientist will use. It won’t use wire-length or resistance. For that matter, he might not know these terms, when you give it the data sets. Look below image:
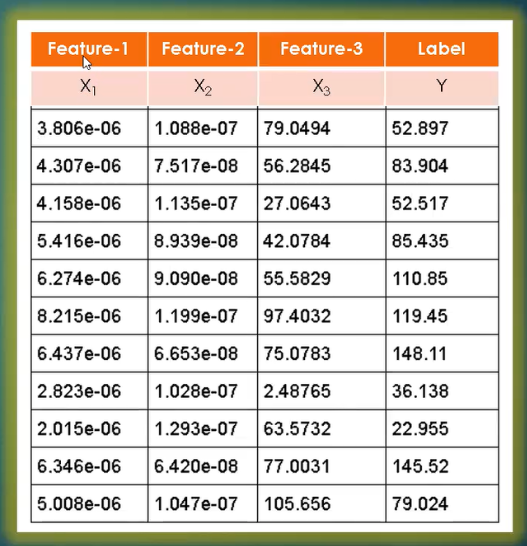
Wire-length, wire-width, temperature will become features, like feature-1, feature-2, feature-3. And the output resistance becomes label. Since you have label and features, this is a supervised class of algorithms. Now, machine learning model is a mathematical function that describes the relationship between these features and labels.
Next step is normalization – very important step. Training is prone to fail if you don’t normalize.
Normalization is a process of scaling feature values in the same order of variation. Look into all columns of above dataset. The first column is pretty much “e-06” (variation in order 1), second column is varying between “e-07” and “e-08” (variation in order 2), third one is the temperature which is ranging between 2degree to 105degree (variation here is in the order of 2). Now observe the variation between first 3 columns (feature sets) is approximately e+10 [from “e+02” (highest) to “e-08” (lowest)]. And that’s large.
When you have such variations, algorithms tend to exhibit unusual behavior. So, you must normalize.
What normalization means? Technique to bring the variations of these data-sets to the same degree, like 0 to 1, 1 to 10 or 1 to 100, in a reasonable order so that the algorithm works fine, and you can train it faster. For EDA applications, where you have frequency ranging to GHz and capacitance is 10e-21, the variation is just 10e+30. Square of 10e+30 (regression model) becomes 10e+60, and immediately it goes beyond the range of largest range of number which a machine can hold.
And below is our machine learning mode – a simple one
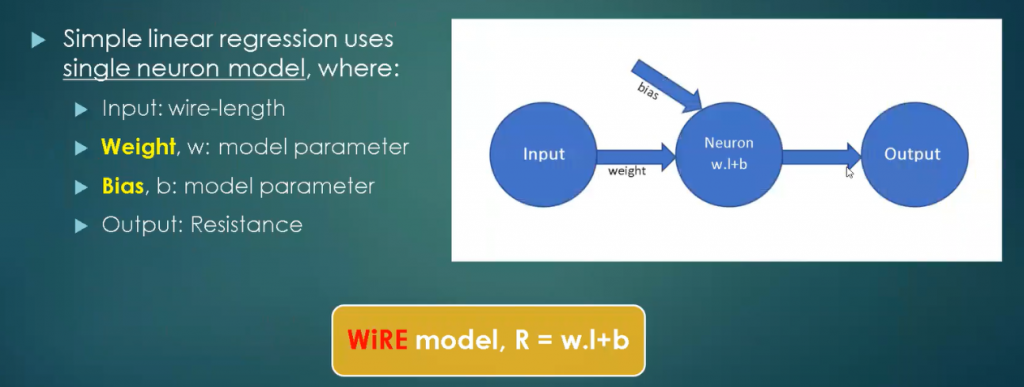
Input is wire-length. And you have 2 variables which are model parameters, weight and bias, and the center blue circle is your model (Neuron w.l + b). It’s a single neuron. What machine learning will do is, find the value of ‘w’ and ‘b’ for you, given the data-set (‘length’). This will look at all 8000 of your samples and it will find ‘w’ and ‘b’ such that, your model is a best fit for all 8000 parameters.
Your learning algorithm would also need “Loss function”, which represents the value loss for the model between 2 sets of parameter values. Let’s say, you have w1 and b1, w2 and b2, both these parameters will give 2 different models. One of them would be better than other. By how much is one better than other, is what Loss function tells you. And you learning algorithm uses this loss function to guide itself, as to which next step it should take to find the global minima. Below “Loss function” model, sums it all – it’s a variation of error [f(xi) – yi]2 multiplied by entire data-set
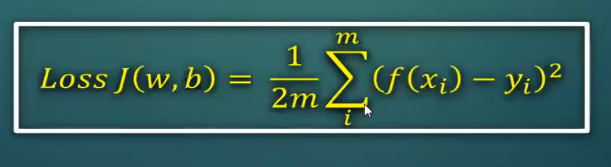
Now all above information and the below course on Machine intelligence should be good enough data for you to start writing a paper and submit in VSDOpen2018
https://www.udemy.com/vsd-machine-intelligence-in-eda-cad/
Machine Intelligence is “most needed topic” for VLSI engineers, if you want to stay ahead of time and be ready for change. So, papers will be very carefully selected for this topic
All your ideas will be reviewed by below panel of session chairs (who are all experts in their domains) and you might just get a chance to showcase your innovation to top crowd from VLSI industries:

The reason for this conference is to do out-of-the-box things in field of VLSI, to showcase your versatility and talent to a lot of TOP people, and get their attention, all online.
“This can be your new creative resume”
All the best for your submissions and happy learning