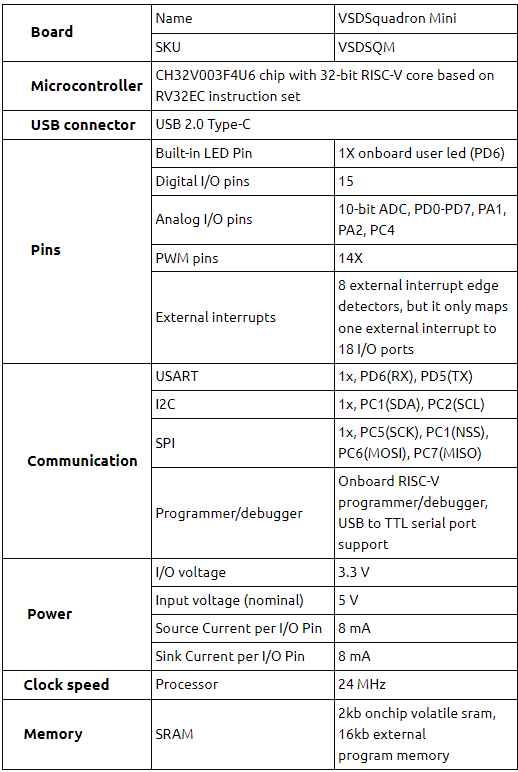
The above waterfall diagram is representing a sequence of instructions that are fetched from memory and how they progress to the various stages of pipeline. In the above diagram you got program counter (P), fetch (F), decode (D), register read (R), execute (E) and register write (W). We fetch one instruction at a time. Potentially, you can fetch multiple instructions at a time, which would be a super-scalar architecture (not sure if any RISC-V implementations are super scalar).
In above image, we are fetching one instruction (ADDI) and then a cycle later, we are fetching next instruction (BGT) initially down the pipeline. The definition of instruction set architecture RISC-V is written in terms of a model, where each instruction is atomically performing its action and computing its results.
Here, in above image, we are distributing that computation, overlapping the execution of each instruction. So, there are various scenarios that can arise, where one instruction has a side-effect that impacts the next instruction, and we don’t yet know that side-effect, in-order to take it into account, when we are executing instruction because we have overlapped the operation of each instruction
We have illustrated in above image, a few situations over here. The second instruction is BGT (branch if greater than). We don’t know whether it takes the branch or not, until we have done a “greater than” comparison in the “E” unit.
If we determine, based on that comparison, that we mis-predicted (mispred) that whether the branch is being taken or not, then design will be taking about “predict fall-through”, meaning sequential execution.
If we determine, that branch should have been taken, we then learn that we have started down about half and the instructions in grey in above image (JAL r4, SUBI, LD, OR) should not have been executed. None of them is far enough to be have been written back in register file and commit any results (W).
So, none of them has not done any harm yet. But at “E” of BGT instruction, we re-direct the PC to branch target (SLL instruction) and fetch that instruction and then we need to squash back the instructions above SLL so that they don’t write back the results in the register file “mispred” one such hazard. And there are some more hazards, like “read after write in register” and many more. Wait for the upcoming blog OR, all of them has been very beautifully covered in below “Pipelining RISC-V” course:
https://www.udemy.com/vsd-pipelining-risc-v-with-transaction-level-verilog/