VSDOpen 2019 Demo 1 : Raven Chip – First-time silicon success with Qflow and Efabless
The Raven chip: First-time silicon success with Qflow and Efabless Raven is a open-source top-level SoC design based […]
The Raven chip: First-time silicon success with Qflow and Efabless Raven is a open-source top-level SoC design based […]
Biodata:Zvonimir Z. Bandić,Chairman of CHIPS Alliance, Chair of OpenCAPI org, and Board of Directors member of RISC-V standards organisation. Zvonimir Z. Bandić is the Research […]
Biodata: Daniel has worked in Silicon Valley for the past 35 years with semiconductor manufacturers, electronic design automation software, and semiconductor intellectual property companies. Daniel […]
Biodata: Calista Redmond is the CEO of the RISC-V Foundation with a mission to expand and engage RISC-V stakeholders, compel industry adoption, and increase visibility […]
Hear it from an expert – Daniel Nenni, founder of SemiWiki.com Daniel Nenni needs no introduction and we all know he runs a very successful […]
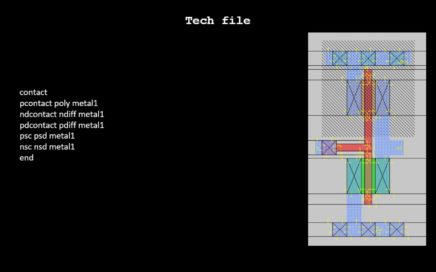
“Research is to see what everybody else has seen, and to think what nobody else has thought” – Let’s prove this by end of this […]
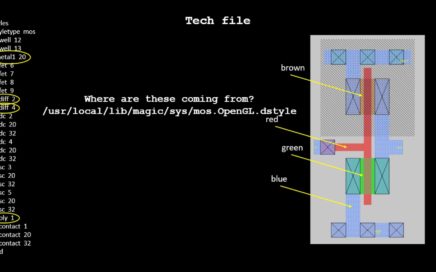
Hey There, This is rather a very curious query I had, when I was learning Magic VLSI Layout tool, and I am very sure, every […]
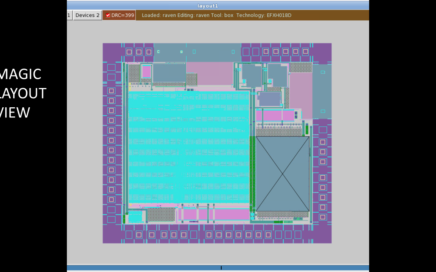
Hey There, Now that it’s clear, that we can tapeout using open-source EDA tools (referring to recent RavenSoC tapeout by Efabless Corp. Pvt. Ltd. using […]
Hey There, Last week, I consulted around 20 colleges to install ‘vsdflow’ on their Linux Ubuntu and CentOS machines. There were many successful installations and […]
to build the shell script for ‘vsdflow’ on CentOS, and finally I have the first cut ready. You just need to follow steps given in below link for CentOS, and all opensource EDA tools (PNR, STA, Layout, LVS) will be installed on your system. There are 2 testcases (picorv32 and spi_slave) inside the below link to test whether all tools have been installed or not. After running the shell script in below link, you need run the testcase